
MIPS 명령어 단일 사이클 데이터패스 구현
서론
모든 명령어의 첫 두 단계는 다음과 같다.
- 프로그램 카운터(PC)를 프로그램이 저장되어 있는 메모리에 보내서 메모리부터 명령어를 가져온다.
- 읽을 레지스터를 선택하는 명령어 필드를 사용하여 하나 또는 2개의 레지스터를 읽는다. (워드 적재 명령어는 레지스터 하나, 대부분의 다른 명령어는 레지스터 2개)
이 두 단계 이후에는 명령어 종류에 따라 필요한 행동들이 다르다. 하지만 세가지 명령어 종류(메모리 참조 명령어, 산술/논리 명령어, 분기 명령어) 각각은 명령어에 상관없이 비슷하다.
점프 명령어를 제외한 모든 명령어가 레지스터를 읽은 후에는 ALU를 사용한다. (주소 계산, 비교, 연산 수행을 위해)
데이터 메모리는 적재 명령어일 때는 읽기, 저장 명령어일 때는 쓰기를 해야한다. 레지스터 파일은 적재 명령어일때만 쓰기를 한다. ALU는 여러 가지 연산 중에 하나를 수행해야한다. 이렇게 연산을 통제하는 역할을 하는게 제어 유닛(control unit)이며 제어선을 통해 연산을 통제한다.
이제 빈 도화지에서부터 데이터패스를 만들어나가보자.
데이터패스 만들기
가장 기본이 되는 구성요소들이다.
- 메모리 유닛 - 명령어를 저장하고 있다가 주소가 주어지면 명령어를 읽어서 보내 줌
- 프로그램 카운터(PC) - 현재 명령어의 주소를 가지고 있는 레지스터
- PC를 다음 명령어 주소로 증가시키는 덧셈기
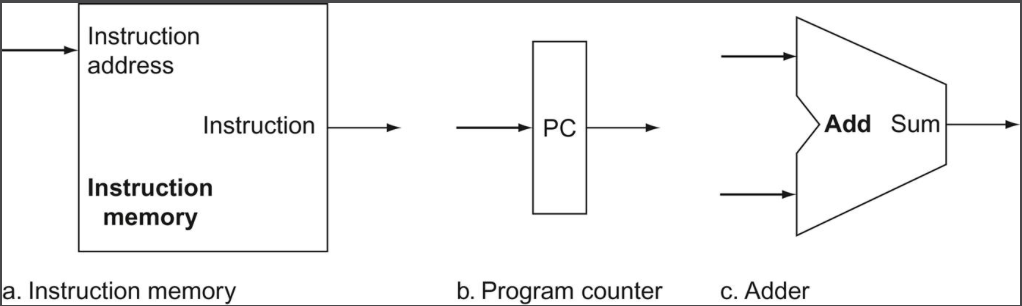
이 세 구성 요소를 합치면 명령어를 인출하고 PC를 증가시켜서 다음 명령어의 주소를 구하는 데이터패스를 만들 수 있다.
R-format 명령어
이제 R-format 명령어들을 생각해보자. R-format 명령어들은 두 개의 레지스터를 읽고 ALU 연산을 수행한 후 레지스터에 쓴다.
ex) add $t1, $t2, $t3 ⇒ $t2와 $t3의 값을 읽어와 더한 뒤 $t1에 결과를 쓴다.
먼저 프로세서의 범용 레지스터 32개는 레지스터 파일(register file)이라는 구조속에 들어있다. 파일내의 레지스터 번호를 지정하면 읽고 쓰는 것이 가능하다.
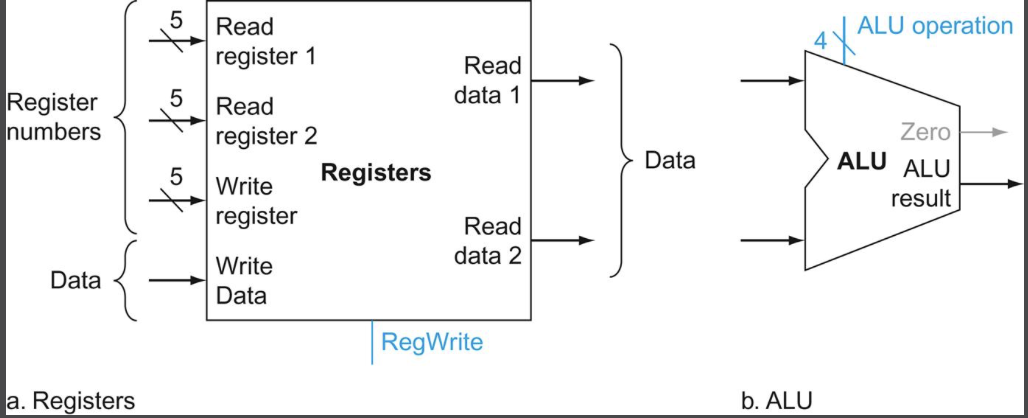
레지스터 파일은 모든 레지스터를 포함하고 있으며 두개의 읽기 포트와 한개의 쓰기포트가 있다. 32개의 레지스터를 표현하려면 5비트가 필요하다. (화살표 위의 5가 의미하는 것이 그것이다. 화살표에 따로 표시가 안되있다면 기본적으로 32비트이다.)
오른쪽의 ALU를 보자. ALU는 두개의 32비트 데이터를 입력받아 32비트 결과 하나와 결과가 0인지 아닌지를 나타내는 1비트 신호를 만든다.
지금까지 나온 구성 요소들을 이용하면 R-format 명령어들의 데이터패스를 만들 수 있다.
적재/저장 명령어
다음으로 MIPS의 적재 명령어(ex lw)와 저장 명령어(ex sw)를 생각해보자.
lw $t1, offset_value($t2)
sw $t1, offset_value($t2)
와 같은 형식을 갖는다. 이 명령어들은 베이스 레지스터 (여기서는 $t2)와 부호있는 16비트 변위 필드 (offset_value)를 더하여 메모리 주소를 계산한다. sw 명령어는 $t1에서 저장할 값을 읽어오고, lw 명령어는 메모리로부터 읽어들인 값을 $t1에 저장한다.
이 과정을 생각해보면 레지스터 파일과 ALU가 둘 다 필요하다는 것을 알 수 있다.
추가로 ALU는 입력으로 32비트 데이터를 받기 때문에 부호있는 16비트 변위 필드를 부호있는 32비트 값으로 sign extension(부호 확장)해 줄 유닛이 필요하고, 읽고 쓸 메모리가 필요하다.
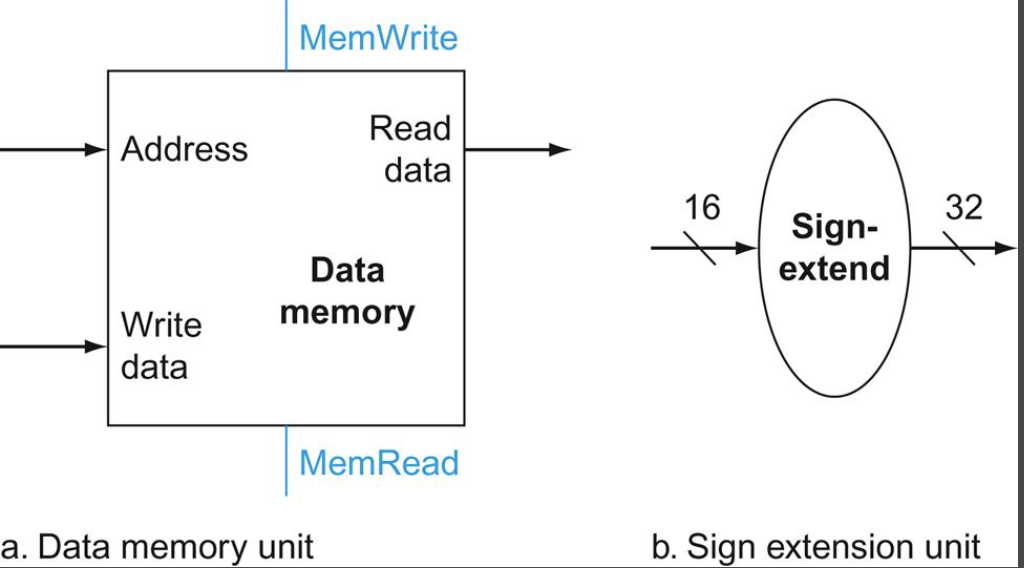
여기서 데이터 메모리 유닛은 저장 명령어 일때만 쓰기를 해야하고, 적재 명령어 일때만 읽기를 해야한다. 따라서 읽기와 쓰기를 제어해줄 제어 신호가 필요하다. 파란색으로 표시된 MemWrite와 MemRead가 그것이다.
오른쪽의 Sign extension unit의 입출력을 보면 16비트를 입력으로 받아 32비트의 출력을 내보내는 것을 볼 수 있다.
지금까지의 유닛들을 이용한 구성으로 적재와 저장 명령어의 데이터패스도 만들 수 있게 되었다.
분기 명령어
다음으로 beq 명령어를 생각해보자. 예시는 다음과 같다.
beq $t1, $t2, offset ⇒ $t1의 값과 $t2의 값이 같으면 offset으로 분기
beq 명령어에서는 두 레지스터의 값을 비교하기 위해 ALU가 필요하고, offset을 주소로 변환하기 위해 Sign extension unit이 필요하다. offset을 주소로 변환하기 위해 주의해야할 점이 두가지 있다.
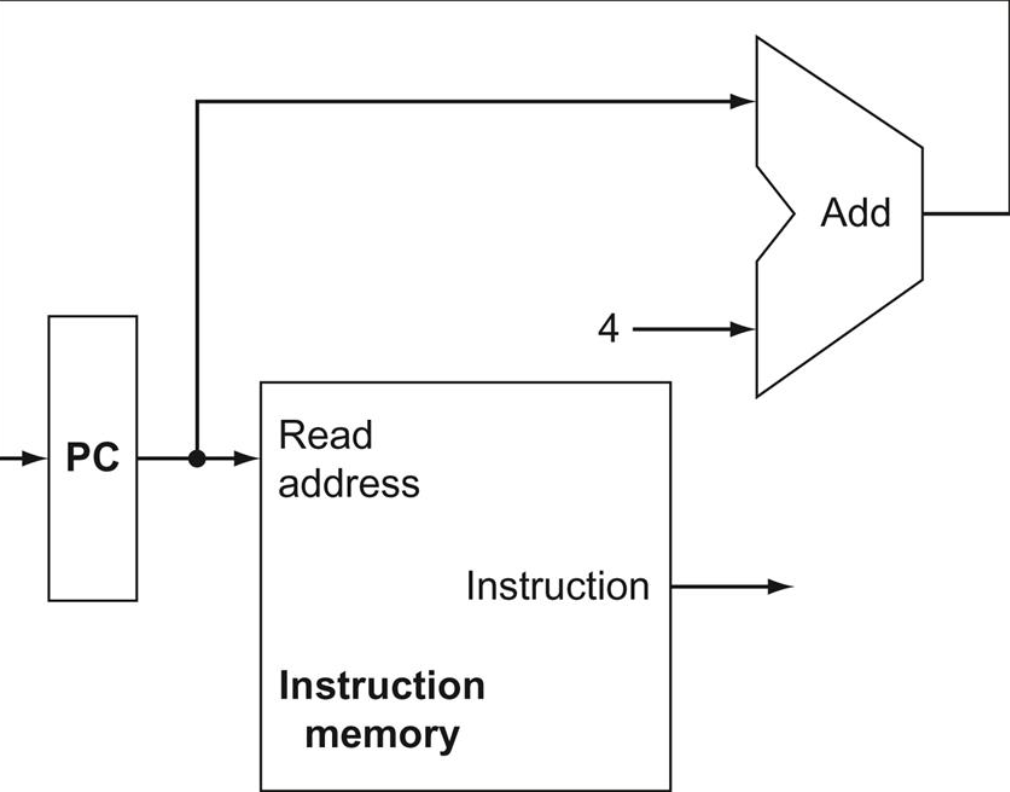
- 베이스 주소는 PC + 4로 해야한다.
- 변위 필드를 2비트만큼 왼쪽으로 자리이동하여 워드 변위로 만들어 유효 범위를 4배만큼 증가시킨다.
1번 문제의 PC + 4는 위의 명령어 인출 데이터패스에서 계산했기 때문에 쉽게 얻을 수 있다.
2번 문제를 다루기 위해서 변위 필드를 왼쪽으로 2비트 자리이동해야하는데, 부호 확장된 변위 필드의 오른쪽에 00을 붙히는 단순한 신호의 통로로 구현할 수 있다. 자리이동 값이 2비트로 고정되어 있기 때문에 실제적인 자리이동 하드웨어는 필요하지 않다.
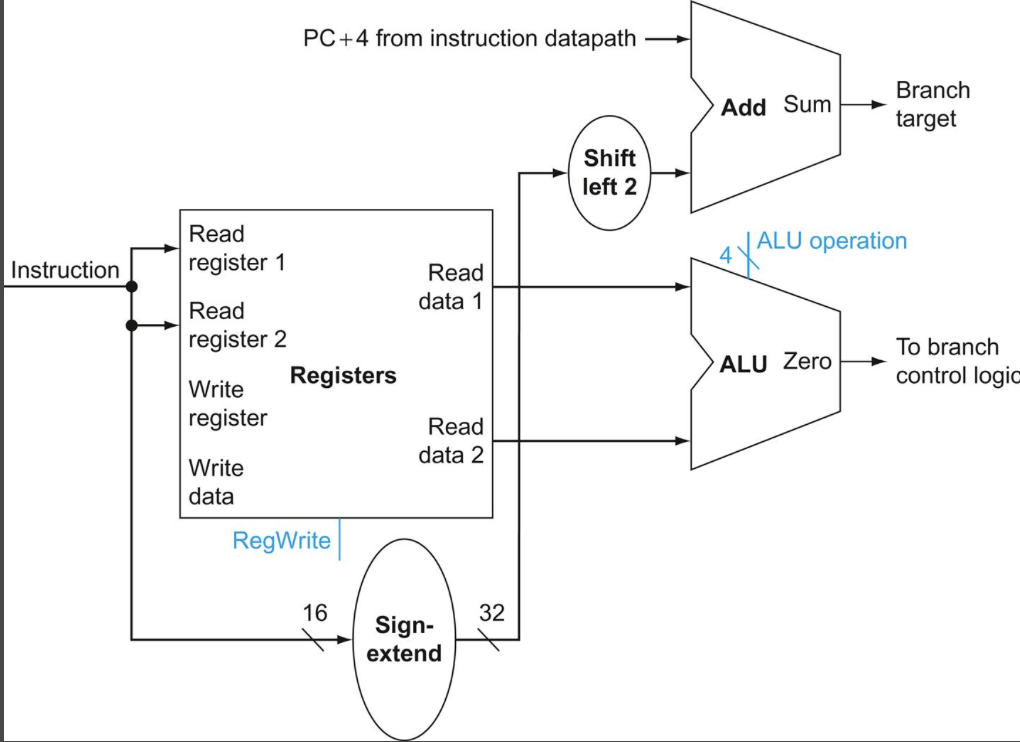
분기를 다루는 데이터패스는 위와 같다. 먼저 아래의 ALU는 레지스터 파일에서 읽어온 두 개의 레지스터 값이 동일한지 판단하는데, ALU에는 결과가 0인지를 나타내는 출력 신호가 존재하기 때문에 두 값을 빼는 연산을 수행해 출력 신호의 값에 따라 두 값이 동일한지 체크할 수 있다.
만약 두 값이 동일하다면 위의 Add 덧셈기에서 계산한 값 (PC + 4 + 부호확장되고 왼쪽으로 2비트 자리이동한 변위필드 값)이 새로운 PC 값이 되고 (이를 branch taken, 분기가 일어났다라고 한다.), 동일하지 않다면 그냥 일반적인 명령어들처럼 PC + 4 의 값이 새로운 PC 값이 된다. (이를 branch not taken, 분기가 일어나지 않았다고 한다.)
jump 명령어는 단순히 명령어의 하위 26비트를 2비트만큼 왼쪽으로 shift한 값으로 PC의 하위 28비트를 대체한다. 간단하게 뒤에 00을 붙히는 것으로 구현할 수 있다.
Combine
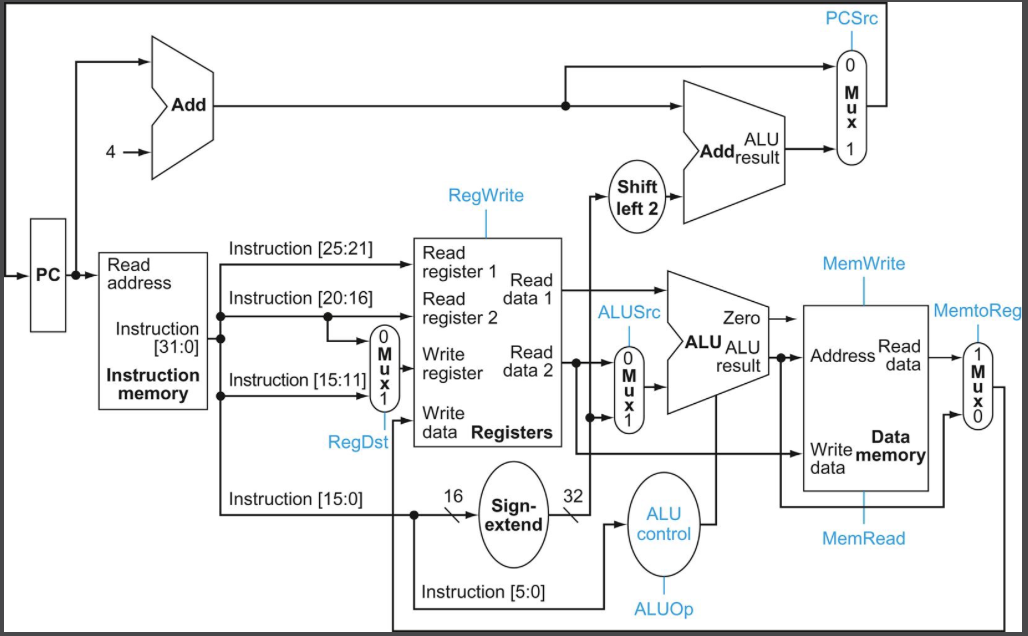
지금까지 각 명령어에 대한 데이터패스를 만드는데 필요한 구성요소들을 짚어보았다. 이제 이 구성요소들을 하나로 묶고 제어만 추가하면 데이터패스 구현을 완성시킬 수 있다. 우리는 모든 명령어를 한 클럭 사이클에 실행하려고 함을 주의하자. 따라서 두 번 이상 사용할 필요가 있는 구성 요소는 필요한 만큼 여러 개를 둔다. 이때문에 데이터 메모리와는 별도로 명령어 메모리가 필요한 것이다.
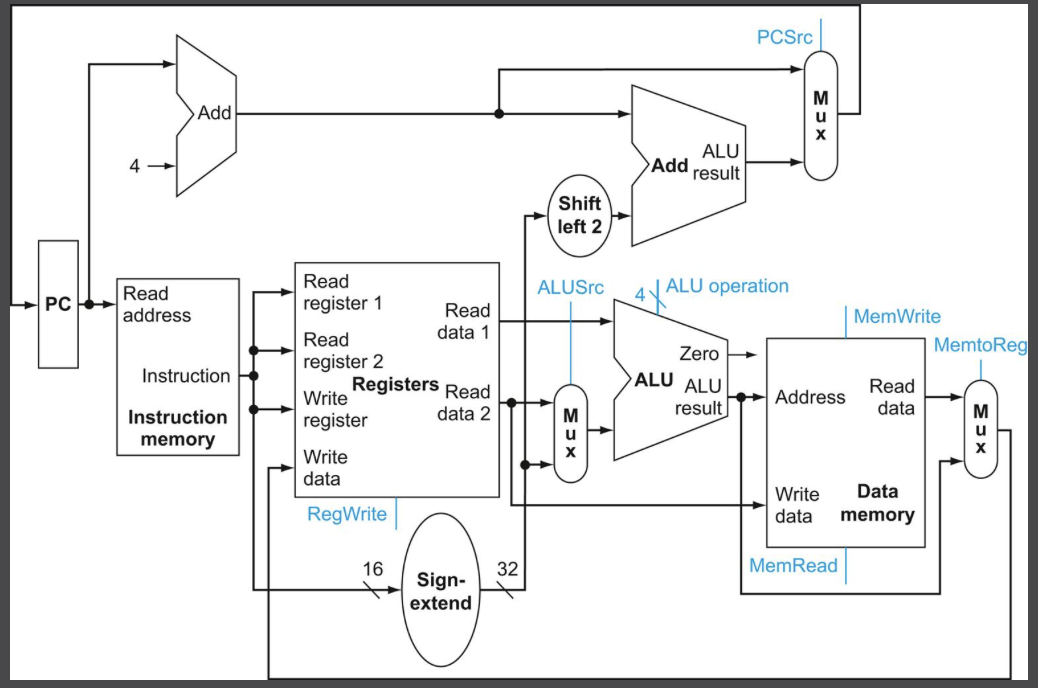
위 그림이 기본 명령어들(적재/저장, ALU 연산, 분기)을 한 클럭 사이클에 실행할 수 있는 데이터패스의 그림이다. 제어는 파란색으로 표시되어 있으며 뒤에서 좀 더 자세히 살펴보겠다. 여기서 Mux(멀티플렉서)는 여러 입력을 받아 하나의 출력으로 선택해주는 역할을 수행한다. 어떤 입력을 선택할지는 제어에 따른다. 데이터패스를 보고 각각의 명령어의 흐름을 잘 생각해보자.
제어 (Control)
이번에는 제어에 대해 좀 더 자세히 살펴보자. 제어는 각 유닛이 어떤 행동을 할지 결정하도록 하는 역할을 수행한다.
ALU operation 제어
예를들어 위의 데이터패스의 ALU 유닛을 제어하는 ALU operation 제어를 보자. 4비트를 통해 ALU가 다음 여섯 가지 조합중 어떤 행동을 하도록 할지 결정하도록 한다.

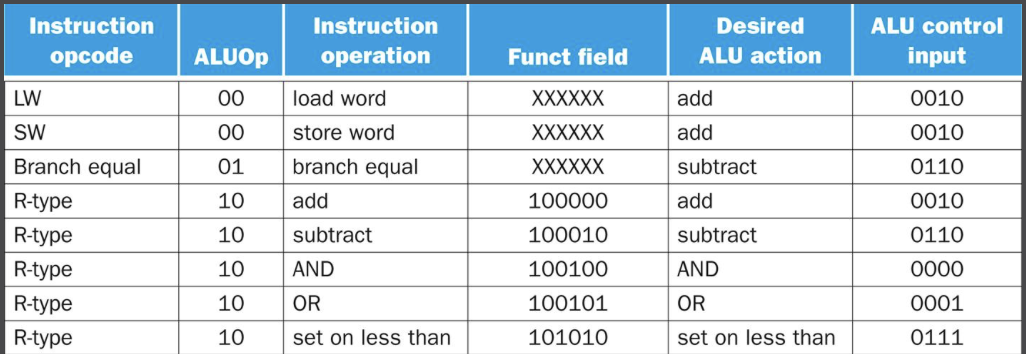
예를들어 ALU operation 제어가 0010 이었다면 ALU는 add 연산을 수행하는 것이다. 적재/저장 명령어라면 add 연산이 필요할 것이고, R-format 명령어라면 각 명령어들에 따라 다섯 가지 연산(AND, OR, add, substract, set on less than) 중 하나가 필요할 것이다. 또한 beq 명령어는 substract 연산이 필요할 것이다.
그렇다면 어떻게 이를 결정할 수 있을까? 명령어 32비트 중 funct 필드와 2비트 제어 필드 (ALUOp라고 불림)을 입력으로 갖는 제어 유닛을 반들어서 4비트 ALU Operation 제어 입력을 발생시킬 수 있다.
ALUOp는 수행할 연산이 덧셈(00)인지(lw와 sw 명령어), 뺄셈(01)인지(beq 명령어), 아니면 funct 필드에 따라 달라지는지(10)를 표시한다.
ALUOp가 ALU operation의 뒤 두비트가 되는 것이다. 앞의 두 비트는 두 입력을 반전시키는 Ainvert와 Binvert이다.
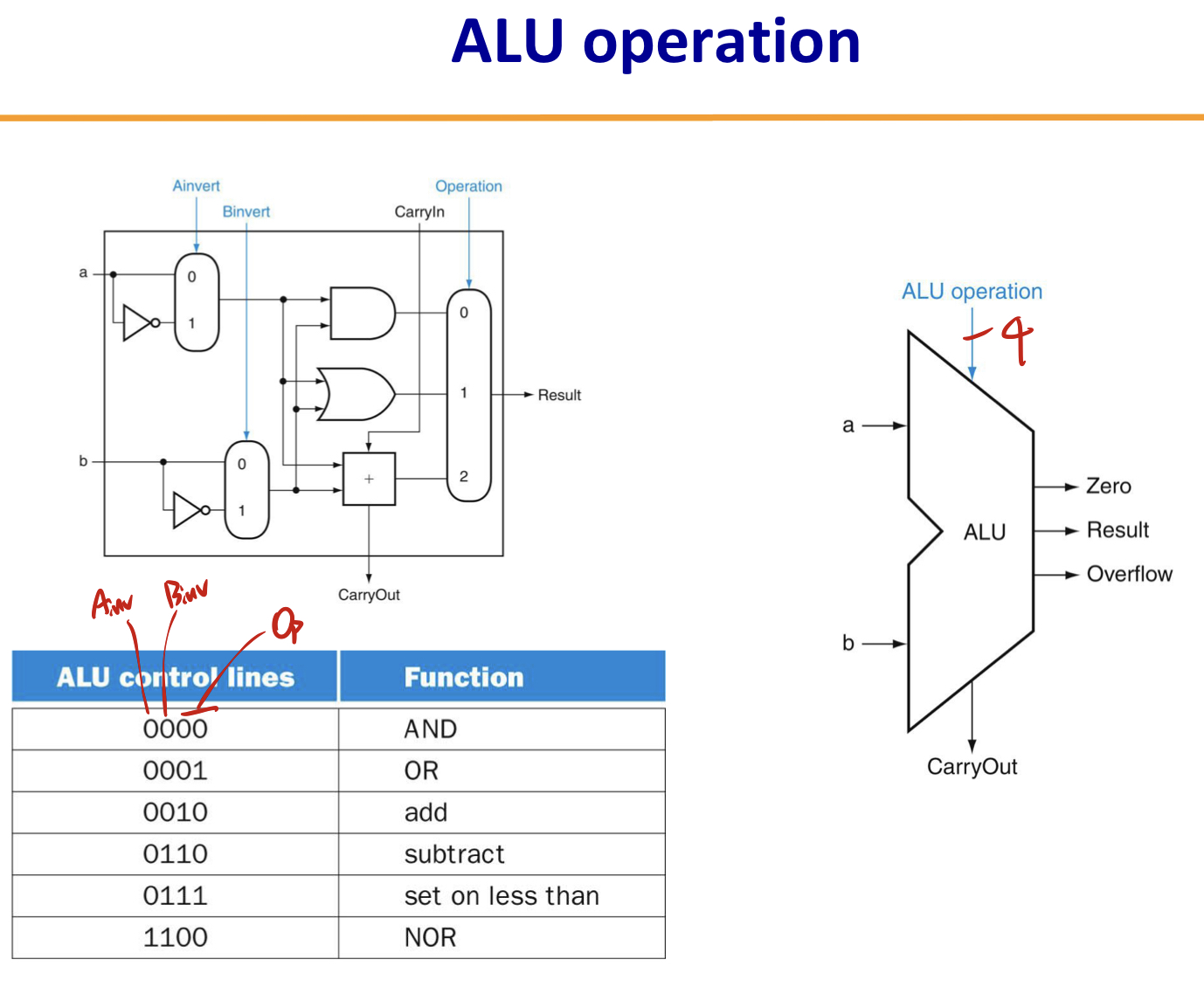
입력을 반전시키는 기능을 추가하는 것만으로 뺄셈과 NOR, NAND를 쉽게 구현할 수 있다.
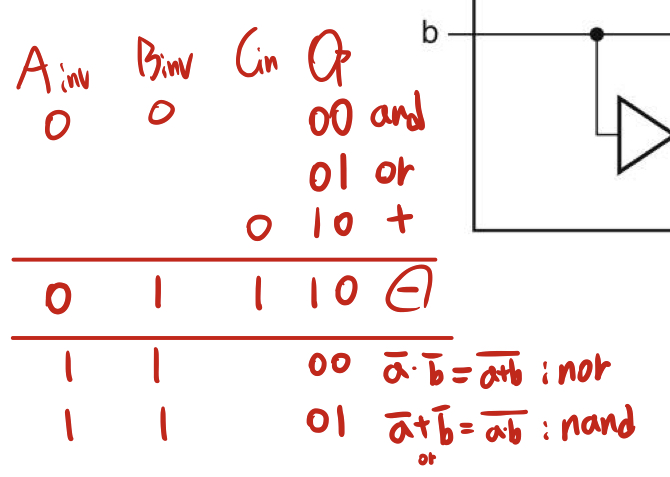
funct 필드에 의해 이 두 비트가 결정된다. ALUOp와 funct 필드 입력으로 출력되는 ALU operation의 진리표는 다음과 같다.
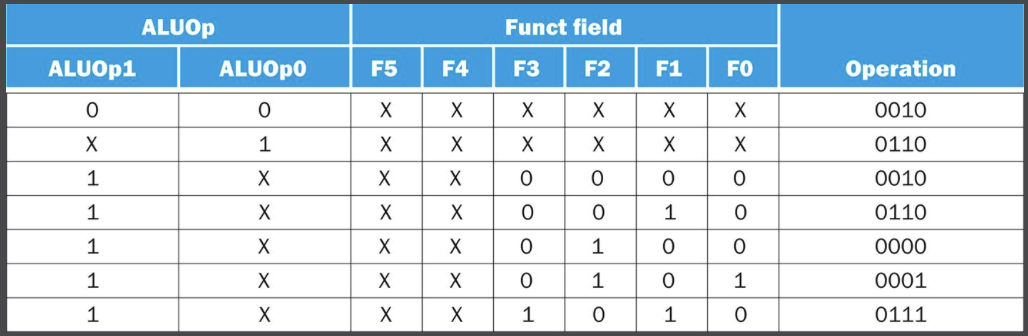
이때 X는 don’t care 항이다. (0이든 1이든 상관 없다는 뜻)
주 제어 (Main control)
이제까지는 funct 필드와 2비트 신호를 입력으로 ALU를 제어하는 유닛을 만드는 과정을 살펴보았다. 이제 나머지 모든 제어를 담당하는 주 제어 유닛을 설계해보자.
그전에 먼저 명령어들의 형식을 다시 한번 짚어보자.

각 명령어 형식의 필드를 잘 이해하고 있어야한다.
명령어 필드와 ALU 제어 유닛, 모든 멀티플렉서와 제어선을 표시하면 다음 그림과 같다.
파란색으로 표시된 제어 신호들의 동작을 먼저 정의해보자.

입력이 두 개인 Mux(멀티플렉서)에 1비트 제어 신호가 들어온다. 제어 신호가 0이면(인가되지 않으면) 0번 입력을, 1이면 (인가되면) 1번입력을 선택한다.
제어선 각각의 기능에 대하여 살펴보았으니 이제 제어선들의 값을 어떻게 해야할지 알아보자. 제어선의 값을 결정하는데에는 opcode 필드만 보고 결정할 수 있다. (PCSrc만 제외하고)
opcode가 무엇인지가 명령어가 해야할 일을 모두 갖고 있는 것이다. 따라서 제어유닛은 opcode를 입력으로 받아서 해당 명령어가 해야할 일을 출력으로 제어하면 되는 것이다. PCSrc는 실행 중인 명령어가 beq이며 동시에 ALU의 Zero 출력이 참일 경우에만 인가(1)된다. 실행 중인 명령어가 beq인 것은 opcode를 보고 제어 유닛이 알 수 있다. 따라서 opcode가 beq인지 확인한 출력과 ALU의 Zero 출력을 AND 연산하면 PCSrc 신호를 만들 수 있다.
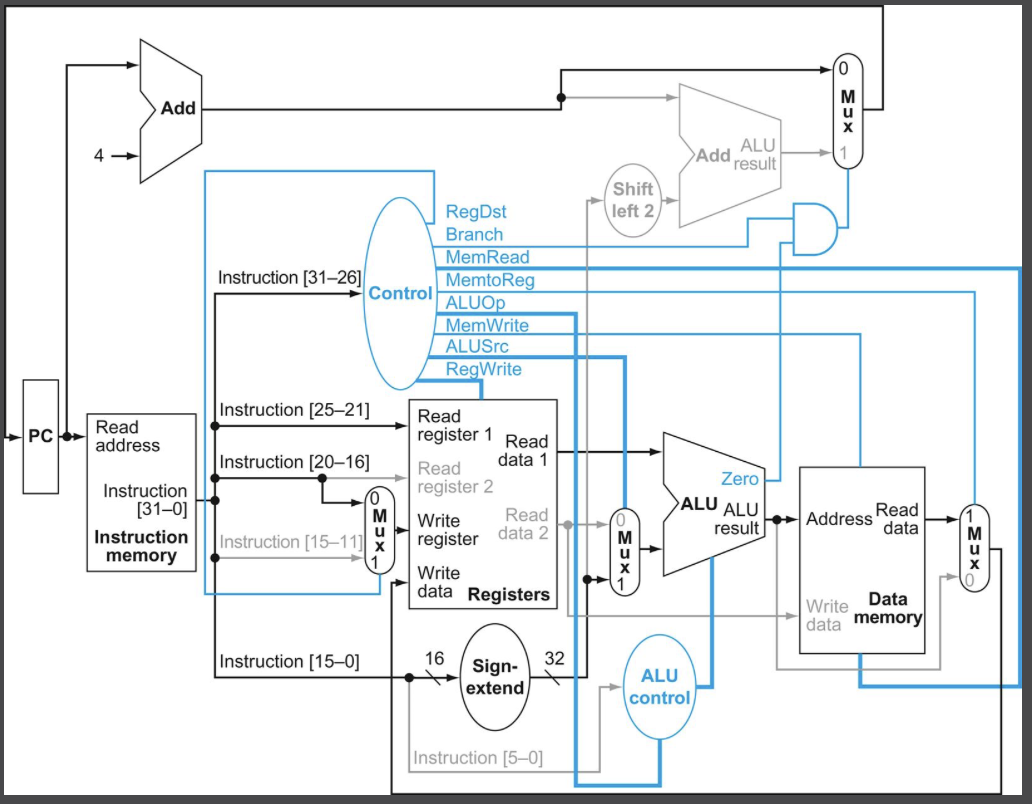
주 제어 유닛을 추가한 데이터 패스이다. 명령어의 31-26번 필드 (opcode)를 입력으로 받고, 출력은 멀티플렉서 제어하는 3개의 1비트 신호 (RegDst, ALUSrc, MemtoReg), 레지스터 파일과 데이터 메모리에서 읽고 쓰는 것을 제어하기 위한 3개의 신호 (RegWrite, MemRead, MemWrite), 분기할지 말지를 판단하는 데 쓰이는 1비트 신호(Branch), ALU를 위한 2비트 제어신호(ALUOp)이다.
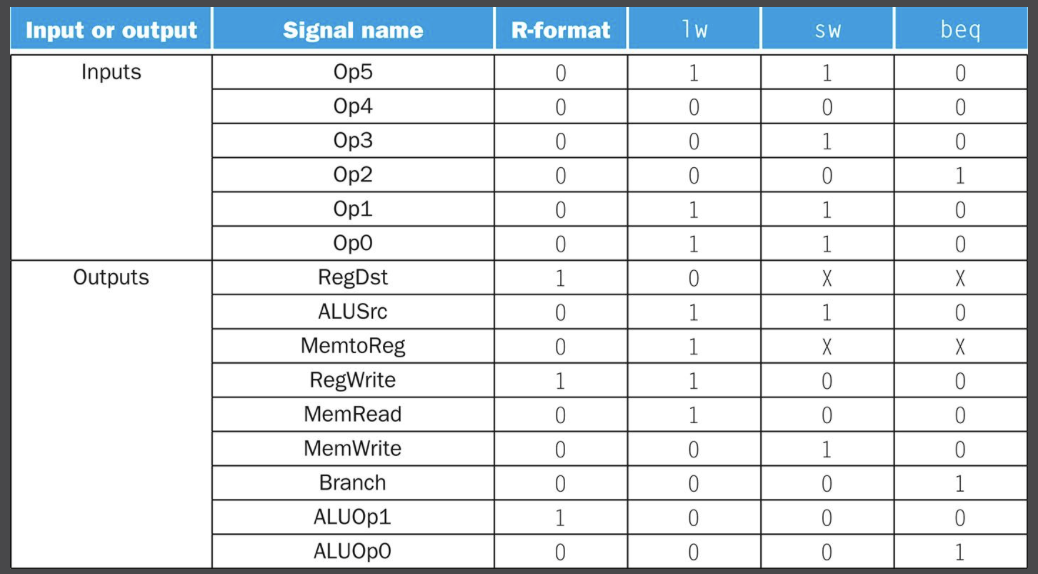
제어신호들의 값과 명령어의 opcode 필드의 관계는 위와 같다.
데이터패스의 동작
완성된 데이터패스가 각각의 명령어 종류에 따라 어떻게 동작되는지 살펴보자.
R-format 명령어
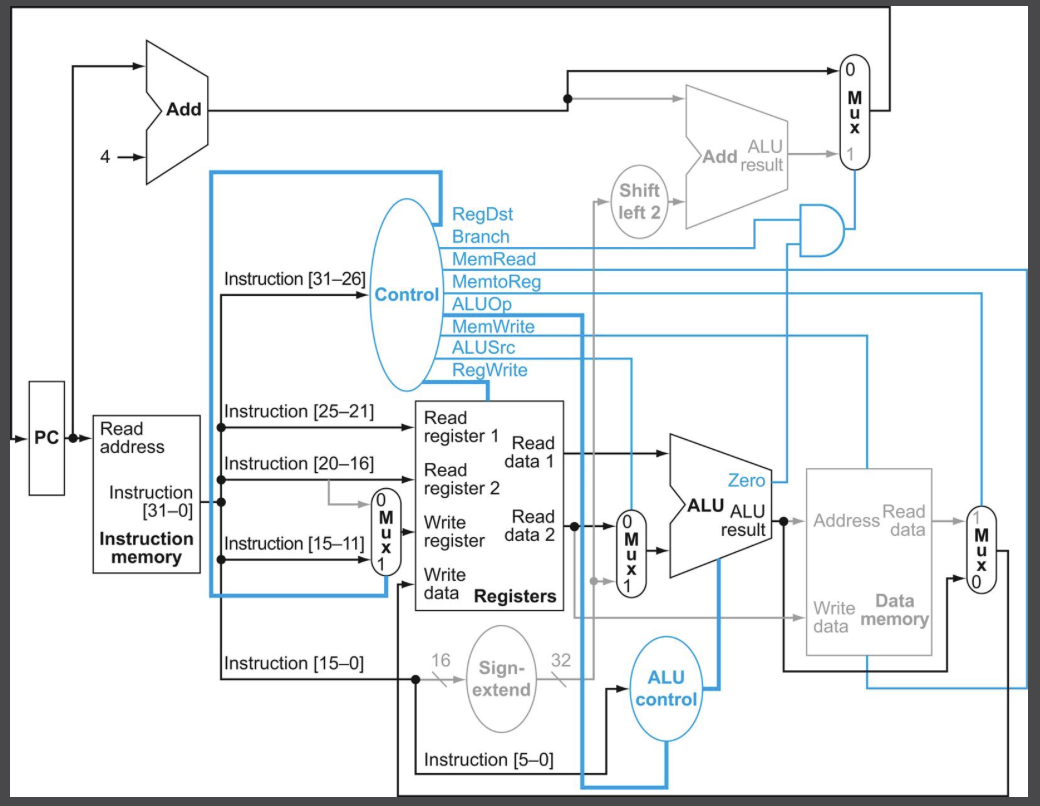
예를들어 add $t1, $t2, $t3 명령어의 과정을 따라가보자.
- 명령어를 인출하고 PC를 증가시킨다.
- 레지스터 파일에서 두 레지스터 $t2(명령어의 25:21 비트), $t3(명령어의 20:16 비트)를 읽는다. 동시에 주 제어 유닛이 제어선의 값들을 결정한다.
- ALUOp와 funct필드(명령어의 5:0 비트)를 이용해 만들어진 ALU operation 제어 신호를 통해 레지스터 파일에서 읽어들인 값들로 연산을 진행한다.
- ALU의 결과 값을 명령어의 15:11 비트로 결정된 $t1 레지스터를 선택해 레지스터 파일에 쓴다.
적재/저장 명령어
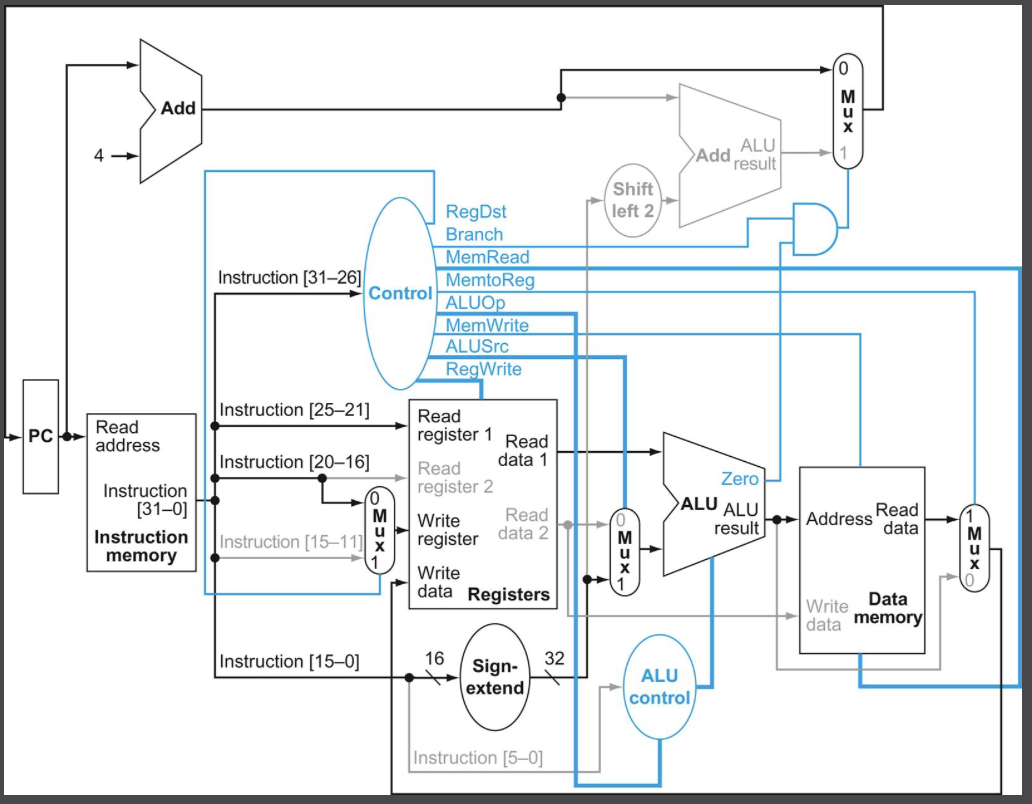
적재 명령어 lw $t1, offset($t2)의 과정을 따라가보자.
- 명령어를 인출하고 PC 값을 증가시킨다.
- 레지스터 파일에서 $t2를 읽는다.
- ALU는 레지스터에서 읽어 들인 값과 offset(명령어의 하위 16비트)를 sign extension한 값의 합을 구한다.
- 이 합을 데이터 메모리 접근을 위한 주소로 사용한다.
- 메모리 유닛에서 가져온 데이터를 명령어의 20:16 비트로 결정된 $t1 레지스터를 선택해 레지스터 파일에 쓴다.
4단계였던 R-format 명령어와 달리 5단계임을 알 수 있다.
분기 명령어
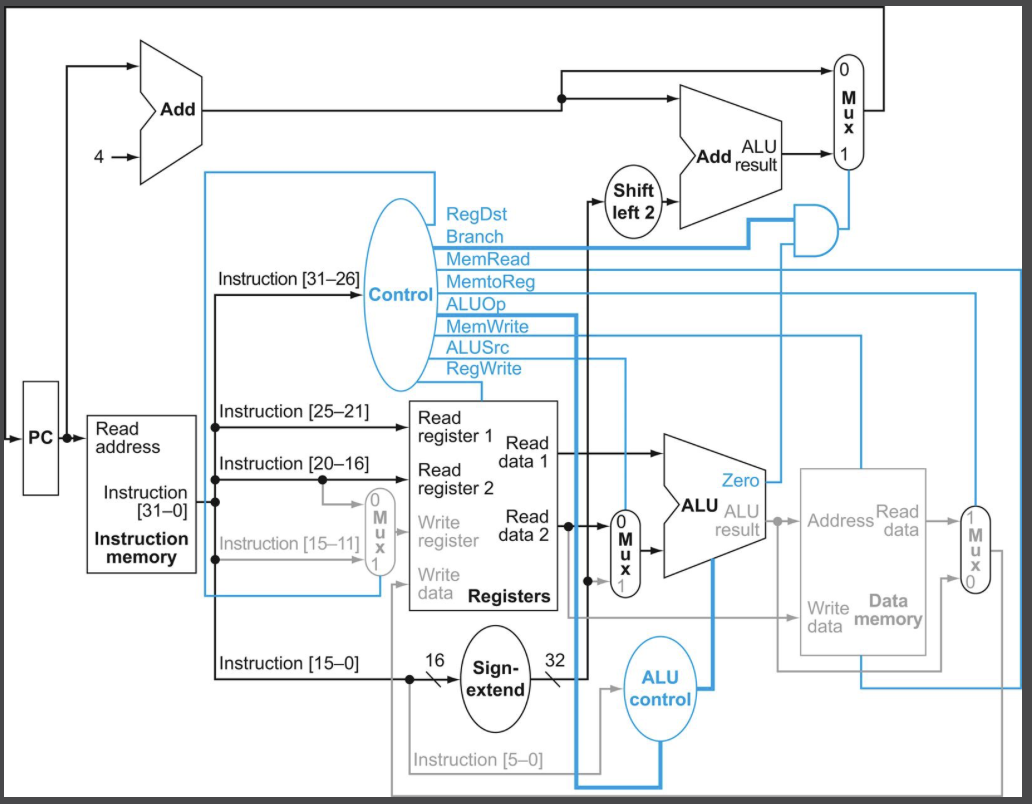
명령어 beq $t1, $t2, offset 의 과정을 따라가보자.
분기 명령어는 R-format 명령어와 유사하게 동작한다. 다만 PC에 PC + 4 값을 넣을 것인지, 분기 목적지 주소를 넣을 것인지를 결정하기 위해 ALU 출력을 사용한다는 점만 다르다.
- 명령어를 인출하고 PC 값을 증가시킨다.
- 레지스터 파일에서 두 레지스터 $t1, $t2를 읽는다.
- ALU는 레지스터에서 읽어 들인 값들에 대해 뺄셈을 진행한다. 동시에 offset(명령어의 하위 16비트)을 sign extension한 후 2비트 왼쪽 자리이동한 값에다 PC + 4 값을 더한다. 이 값이 분기 목적지 주소가 된다.
- PC + 4 와 분기 목적지 주소중 어떤 결과를 PC에 저장할지 ALU의 Zero 출력을 이용하여 결정한다.
결론
이번 기회에 MIPS 명령어를 단일 사이클 데이터패스로 구현하는 과정을 공부해보았다. 단일 사이클 설계는 올바르게 작동하고, 쉽게 구현할 수 있지만 비효율성 때문에 현대의 설계에서는 사용하지 않는다. 단일 사이클 설계에서는 클럭 사이클이 모든 명령어에 대해 같은 길이를 가져야 하는데, 가능한 경로중 가장 긴 경로에 의해 결정된다. (lw 명령어가 명령어 메모리, 레지스터 파일, ALU, 데이터 메모리, 레지스터 파일의 순서로 5개의 기능 유닛을 사용하므로 가장 길것이다.)
단일 사이클 구현은 클럭 사이클이 너무 길기 때문에 전체 성능이 좋지 않다. 이때문에 현대적 설계는 대부분 파이프라이닝이라는 구현 기술을 이용한다. 다음 글에서는 파이프라이닝에 관해 자세히 알아보겠다.
Leave a comment