
데이터베이스 정규화 - Database Normalization
제 1 정규화 (1st Normal Form, 1NF)
제 1 정규화는 한 컬럼에 한 정보만 담는 것이다.
| ID | 학생명 | 과목명 |
|---|---|---|
| 101 | 김동민 | 운영체제, 컴퓨터구조 |
| 102 | 만쥬 | 운영체제 |
| 103 | 춘장 | 컴퓨터구조 |
위의 테이블은 제 1 정규화를 만족하지 못한다.
이러한 경우에 컴퓨터구조를 수강하는 학생들의 정보를 보고싶으면 단순한 where 문으로는 불러오기 힘들고 LIKE ‘%컴퓨터구조%’ 와 같은 문을 추가로 작성해야한다.
따라서 한 컬럼에 하나의 정보만 담고 차라리 row를 늘리는 것이다.
제 1 정규화를 만족하는 테이블로 만들어보면 다음과 같다.
| ID | 학생명 | 과목명 |
|---|---|---|
| 101 | 김동민 | 운영체제 |
| 101 | 김동민 | 컴퓨터구조 |
| 102 | 만쥬 | 운영체제 |
| 103 | 춘장 | 컴퓨터구조 |
이렇게 고치면 단순한 where 문만으로도 컴퓨터구조를 수강하는 학생들의 정보를 불러올수 있다.
제 2 정규화 (2nd Normal Form, 2NF)
| ID | 학생명 | 과목명 | 수업시간 |
|---|---|---|---|
| 101 | 김동민 | 운영체제 | 90분 |
| 101 | 김동민 | 컴퓨터구조 | 180분 |
| 102 | 만쥬 | 운영체제 | 90분 |
| 103 | 춘장 | 컴퓨터구조 | 180분 |
| 104 | 건덕이 | 모바일프로그래밍 | 120분 |
| 105 | 건구스 | 운영체제 | 90분 |
위와 같은 테이블이 존재한다고 가정하자. 이때 운영체제의 수업시간이 60분으로 변경되었다고 하면, 운영체제를 듣고있는 모든 학생들의 수업시간을 변경해야한다. 이 비효율을 줄이는 정규화가 제 2 정규화이다.
위 테이블을
table1 table2
| ID | 학생명 | 과목명 | : | : | 과목명 | 수업시간 | |
|---|---|---|---|---|---|---|---|
| 101 | 김동민 | 운영체제 | : | : | 운영체제 | 90분 | |
| 101 | 김동민 | 컴퓨터구조 | : | : | 컴퓨터구조 | 180분 | |
| 102 | 만쥬 | 운영체제 | : | : | 모바일프로그래밍 | 120분 | |
| 103 | 춘장 | 컴퓨터구조 | : | : | |||
| 104 | 건덕이 | 모바일프로그래밍 | : | : | |||
| 105 | 건구스 | 운영체제 | : | : |
이렇게 두개의 테이블로 나누면 운영체제의 시간이 변경되었을 때 오른쪽테이블의 운영체제 정보만 수정하면 간단하게 정보를 수정할 수 있다. 이렇게 하나의 테이블을 여러 테이블로 나누는 과정을 Decomposition 이라고 한다.
다만 이때의 단점은 학생의 수업시간 정보가 궁금한 경우에 두 테이블을 함께 검색해야한다는 단점이 생긴다.
간단히 말해 제 2정규화는 현재 테이블의 주제와 관련없는 정보를 다른 테이블로 빼는 작업이다. 위 예시에서 수업시간 칼럼은 과목에 종속된 정보로 다른 컬럼과는 관련성이 없다.
이러한 종속적인 관계를 Partial Dependency 라고 하고 제 2정규화는 Partial Dependency를 없애는 정규화이다.
- 자세한 설명
첫 테이블에서 primary key는 하나의 컬럼으로는 하나의 unique한 row를 지정할 수없으므로 불가능하다. 따라서 { ID, 과목 }과 같이 두개의 컬럼을 primary key로 이용해야하고, 이를 composite primary key라고 한다. 이때 수업시간 컬럼의 값은 composite primary key중 과목컬럼에만 종속되어있는 Partial Dependency를 갖고있으므로 제 2정규화는 이를 없애는 작업이다.
제 3 정규화 (3rd Normal Form, 3NF)
| 과목명 | 교수명 | 수업시간 |
|---|---|---|
| 운영체제 | 진철수 | 90분 |
| 컴퓨터구조 | 박철수 | 180분 |
| 컴퓨터회로 | 박철수 | 120분 |
| 모바일프로그래밍 | 지영희 | 120분 |
이 테이블을 보자. 우선 primary key가 과목컬럼으로 composite primary key가 아니므로 제 2 정규화를 만족한다고 할 수 있다. 이때 교수님들의 출신 대학 정보를 추가해보자.
| 과목명 | 교수명 | 출신 대학 | 수업시간 |
|---|---|---|---|
| 운영체제 | 진철수 | 제 2대학 | 90분 |
| 컴퓨터구조 | 박철수 | 제 1대학 | 180분 |
| 컴퓨터회로 | 박철수 | 제 1대학 | 120분 |
| 모바일프로그래밍 | 지영희 | 제 3대학 | 120분 |
이때 출신대학 컬럼은 primary key가 아닌 일반 컬럼인 교수명에 종속된 컬럼이다. 제 3정규화는 이렇게 primary key가 아닌 컬럼들 중에서 일반 컬럼에 종속된 컬럼을 다른 테이블로 분리해내는 정규화이다. 따라서 위의 테이블을 제 3정규화를 만족하게 decomposition하면 다음과 같다.
table1 table2
| 과목명 | 교수명 | 수업시간 | : | : | 교수명 | 출신 대학 | |
|---|---|---|---|---|---|---|---|
| 운영체제 | 진철수 | 90분 | : | : | 진철수 | 제 2대학 | |
| 컴퓨터구조 | 박철수 | 180분 | : | : | 박철수 | 제 1대학 | |
| 컴퓨터회로 | 박철수 | 120분 | : | : | 지영희 | 제 3대학 | |
| 모바일프로그래밍 | 지영희 | 120분 | : | : |
이렇게 하면 박철수 - 제 1대학이라는 데이터의 중복을 줄일 수 있다.
보이스 코드 정규화 (Boyce-Codd Normal Form, BCNF)
정의상으로 아래 조건을 만족시키면 BCNF를 만족한다고 할 수 있다.
X -> Y 는 trivial FD 이거나, X 는 relation R 의 superkey이다.
예시를 보자.
| 학생명 | 과목명 | 교수명 |
|---|---|---|
| 김동민 | 운영체제 | 진철수 |
| 김동민 | 컴퓨터구조 | 박철수 |
| 건덕이 | 모바일프로그래밍 | 지영희 |
| 건구스 | 운영체제 | 진철수 |
| 만쥬 | 운영체제 | 김철수 |
위와 같은 테이블을 가정해보자. 이때 primary key는 { 학생명, 과목명 } 으로 composite primary key이다.
이 테이블의 종속 관계를 그림으로 나타내면 다음과 같다.
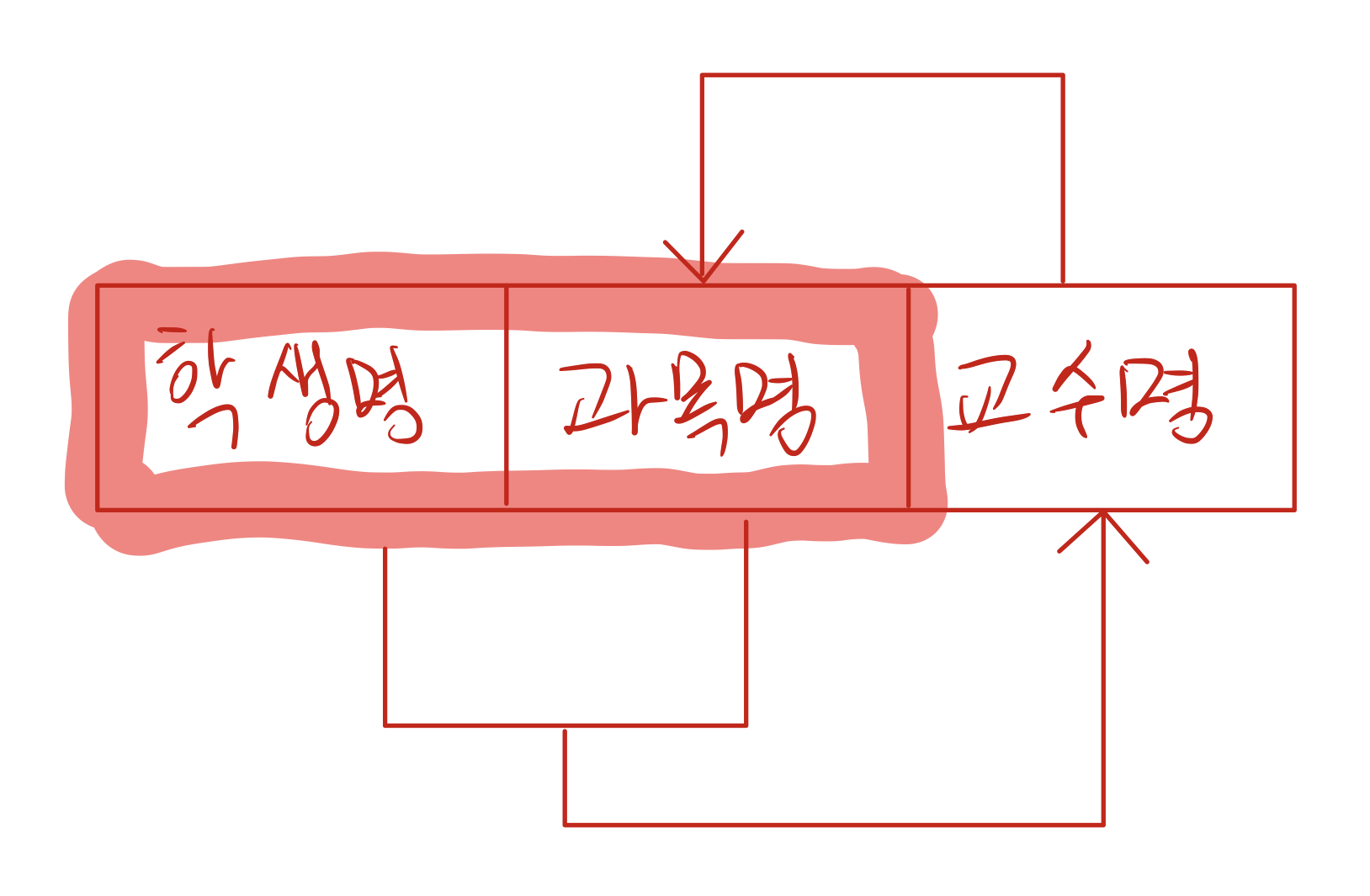
이 때 partial dependency가 없으므로 2NF를 만족하고, primary key가 아닌 컬럼들 중 일반 컬럼에 종속된 컬럼도 없으므로 3NF를 만족한다고 할 수 있다. 하지만 이 때 결정자인 교수명 컬럼이 superkey가 아니므로 BCNF를 위반한다. 이럴경우에는 다음과 같은 문제가 발생한다.
-
삽입 이상
새로운 과목이 개설되었을때, 수강하는 학생이 없는 경우 삽입이 불가능하다. -
갱신 이상
진철수가 강의하는 과목을 변경하고 싶을 때 진철수의 수업을 듣는 모든 학생의 row를 갱신해주어야한다. 이 때 하나라도 빠뜨리면 데이터 불일치 문제가 발생한다. -
삭제 이상
건덕이가 자퇴하여 모바일프로그래밍의 수강생이 없어지면 지영희라는 교수도 사라져버린다.
이러한 문제를 해결하기 위해서는 BCNF를 만족시키기 위해 decomposition을 할 필요가 있다. BCNF를 만족시키기 위한 decomposition의 과정은 다음과 같다.
- BCNF 를 위반하는 nontrivial FD X -> Y 를 찾는다.
- 두 개의 릴레이션으로 분해한다.
- XY 로 구성된 릴레이션 하나
- X 와 나머지 속성들로 구성된 릴레이션 하나
위 과정을 예시에 대입해보면 현재 위반하는 관계는 교수명 → 과목명 이므로 다음과 같이 decomposition 할 수있다.
table1 table2
| 학생명 | 교수명 | : | : | 교수명 | 과목명 | |
|---|---|---|---|---|---|---|
| 김동민 | 진철수 | : | : | 진철수 | 운영체제 | |
| 김동민 | 박철수 | : | : | 박철수 | 컴퓨터구조 | |
| 건덕이 | 지영희 | : | : | 지영희 | 모바일프로그래밍 | |
| 건구스 | 진철수 | : | : | 김철수 | 운영체제 | |
| 만쥬 | 김철수 | : | : |
이렇게 테이블을 분해하면 상기한 문제들을 해결할 수 있다.
결론
데이터 정규화의 목적은 테이블의 중복된 데이터를 허용하지 않음으로써 무결성을 유지하고 DB의 유연성을 높임과 동시에 이상(Anomaly) 현상을 없애는 데에 있다. 각 정규화의 정의와 decomposition의 과정을 잘 알아 두어야겠다.
참고 내용 출처
https://yaboong.github.io/database/2018/03/10/database-normalization-2/
https://www.youtube.com/watch?v=Y1FbowQRcmI&ab_channel=%EC%BD%94%EB%94%A9%EC%95%A0%ED%94%8C/
Leave a comment