
Multi-Thread, Race condition
Multi-Process and Multi-Thread
프로세스(Process)는 OS로부터 자원을 할당받는 작업의 단위, 스레드(thread)는 프로세스가 할당받은 자원을 이용하는 실행의 단위
멀티 프로세스 VS 멀티 스레드
- 멀티 프로세스 : 여러개의 독립적인 프로세스가 각각의 메모리 공간을 가지고 실행된다. 각 프로세스는 OS로부터 별도의 자원을 할당받아 실행된다. 프로세스간 데이터를 주고받으려면 IPC(Inter-Process-Communication) 매커니즘이 필요하다.
- 멀티 스레드 : 하나의 프로세스 내에서 여러개의 스레드가 동시에 실행된다. 각 스레드는 프로세스의 메모리를 공유하며, 스레드 간에는 데이터 및 자원의 공유가 가능하다.
멀티 프로세스는 각각의 프로세스들이 독립적으로 실행되므로 안정성과 격리성이 높지만, 프로세스 간 context-switch의 오버헤드가 크다. 이에 비해 멀티 스레드에서는 각각의 스레드들이 한 프로세스 내에서 경량으로 생성되고 전환되기 때문에 오버헤드가 낮아 성능상 이점이 있다. 하지만 스레드 간의 동기화에 주의해야하며, 잘못된 동기화는 race condition, deadlock 등 여러 문제를 야기한다.
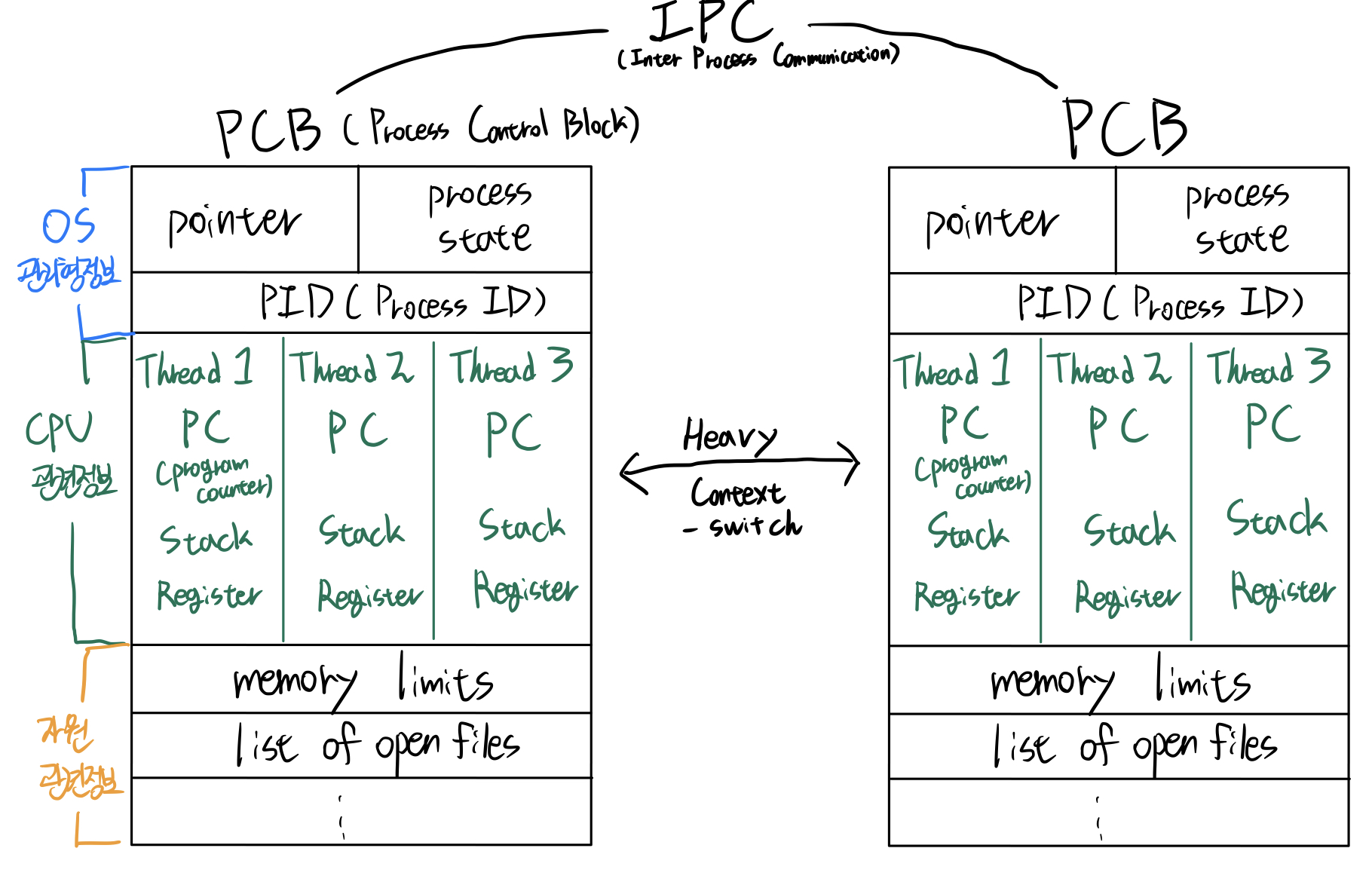 프로세스의 상태 정보를 담고있는 구조체를 PCB(Process Control Block)라고 한다.
프로세스의 상태 정보를 담고있는 구조체를 PCB(Process Control Block)라고 한다.
현재 PCB를 저장하고 다른 프로세스의 PCB정보를 불러오는 것으로 context-switch 할 수 있다. 이는 스레드간 context-switch보다 큰 오버헤드를 발생시킨다.
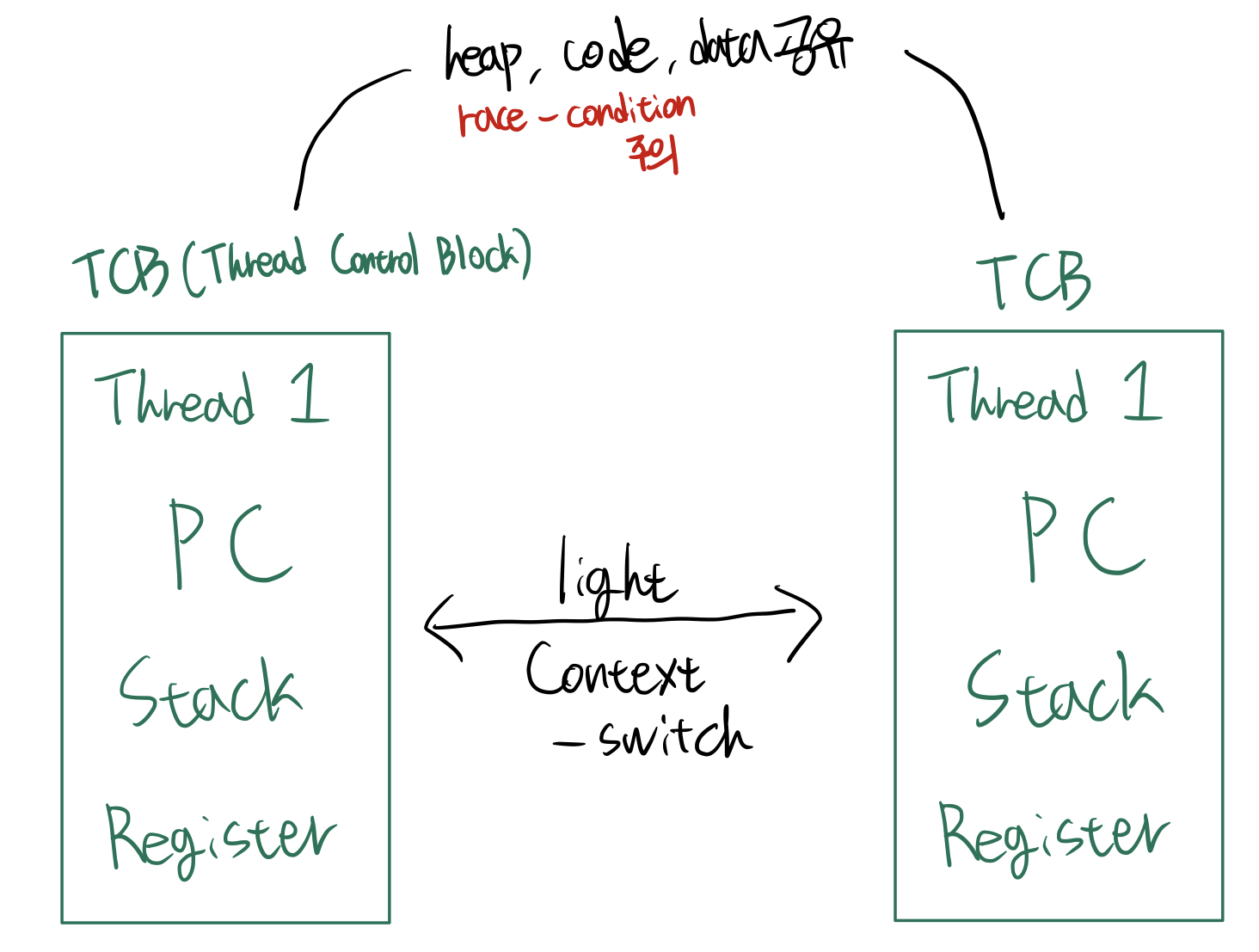
마찬가지로 스레드의 상태정보를 담고있는 구조체를 TCB(Thread Control Block)이라고 하고, 현재 TCB를 저장하고 다른 스레드의 TCB정보를 불러오는 것으로 context-switch 할 수 있다. 각 스레드들은 각자의 PC(Program Counter, 다음 명령어의 주소를 담고 있는 레지스터), Stack(지역변수, 함수 호출 정보, …) 레지스터를 갖고있다. 다만 heap(동적할당된 메모리)영역, code(프로그램 실행 코드)영역, data(전역변수)영역 등은 프로세스 내 모든 스레드들이 공유한다. 그렇기에 공유되는 데이터들의 race-condition에 주의해야한다.
멀티 스레드를 이용하는 이유
-
Parallelism(병렬성)
현대의 CPU들은 다수의 코어를 갖고 있고, 하나의 실행단위가 일을 처리하는 방식은 코어의 낭비로 매우 비효율적이다. 멀티 스레드를 통해 일을 훨씬 효율적이고 빠르게 처리할 수 있다.
-
Avoid blocking
하나의 스레드가 일을 처리하는 시스템에서는 스레드가 I/O 작업으로 block 상태에 들어가게 되면, 다른 일을 처리할 수 없다. 하지만 멀티 스레드 시스템에서는 하나의 스레드가 block 상태에 들어가도 나머지 스레드들이 다른 job들을 처리할 수 있다.
이러한 장점들 때문에 웹서버, DBMS(DataBase Management System) 등 현대의 많은 응용 프로그램들은 멀티스레드를 구현에 이용한다.
Race condition (경쟁 상태)
Race condition은 멀티 프로세스 또는 멀티 스레드 시스템에서 나타날 수 있는 대표적인 문제들 중 하나이다. 이 글에서는 멀티 스레드에서의 Race condition에 초점을 맞춰 설명해보겠다.
한 프로세스 내의 스레드들은 위에서 설명했듯이 공유된 데이터와 자원들을 이용한다. 이때 동시에 여러개의 스레드가 같은 자원에 접근에 조작하려하면 의도하지 않은 결과를 만들어낸다. 다음 예시를 보자.

pthread create으로 생성된 두 스레드가 전역변수로 선언된 counter 변수에 접근해 1씩 증가시키는 프로그램이다. 반복문을 천만번씩 반복하므로 의도대로라면 counter의 값은 2천만이 되어야할 것이다. 하지만 결과를 확인해보면

2천만보다 작은 결과를 볼 수 있다. 왜 이런일이 일어나는 것일까?
counter = counter + 1;
위 코드는 C 코드 상으로는 한 줄이지만, 내부적으로는 세 번의 명령어로 실행된다. 하나씩 살펴보자.
100 mov 0x8049a1c, %eax
105 add $0x1, %eax
108 mov %eax, 0x8049a1c
먼저 mov 명령어로 메모리상의 counter 변수(주소가 0x8049a1c라고 가정)에 담겨있는 값을 %eax 레지스터로 이동시킨다. 그 후 add 명령어로 레지스터의 값을 1 증가시키고, mov명령어로 레지스터의 값을 다시 메모리의 counter 변수에 저장하는 것이다. 각 명령어 앞의 숫자들은 명령어가 존재하고 있는 메모리의 주소이다.

프로그램의 실행 과정을 나타내면 위 그림과 같다. 세 명령어의 주소가 100, 105, 108이고, 전역변수인 counter는 두 스레드가 공유함을 잘 기억하자.
1번 스레드가 add 명령어까지 수행하면 1번 스레드의 TCB에는 PC값은 108, %eax 레지스터의 값은 51로 기록되어있을 것이다. 이때 OS의 스케줄링에 의해 context-switch가 발생하면 OS는 현재 TCB값을 저장하고 2번스레드의 TCB값을 불러올 것이다.
그 후 2번 스레드가 counter에 저장되어 있던 50의 값을 %eax 레지스터로 가져오고, 1증가시킨 뒤 다시 counter 변수에 해당 값 51을 저장한다.
다시 1번 스레드로 context-switch가 발생하면 아까 저장했던 1번 스레드의 TCB값을 불러오고, 다음 명령어인 mov 명령어를 수행한다. %eax 레지스터에 저장되어 있던 값은 51이므로 counter 변수는 변동없이 그대로 51이 된다.
우리는 각 스레드가 한번씩 counter변수를 증가시키기를 기대했지만, 값이 1만 증가한 결과를 볼 수 있다. 물론 OS의 스케줄링에 따라 의도한대로 순서를 지켜 실행될수도 있지만, 위와같은 결과가 발생할 수도 있는 것이다. 이때문에 counter 변수의 값이 최종적으로 기대했던 값인 2천만이 아닌 그보다 작은 결과를 나타냈던 것이다.
이런 현상은 결국 counter = counter + 1 이라는 코드가 내부적으로는 세 명령어로 이루어져있고, 그 세 줄의 명령어 블록을 통해 여러개의 스레드가 공유하는 자원인 counter 변수에 동시에 접근하면서 발생하는 문제이다. 이렇게 공유 자원에 동시에 여러 스레드가 접근하여 의도하지 않은 결과를 만들어 내는 것을 race condition, 경쟁 상태라고 한다.
또한 race condition을 발생시키는 영역, 위의 예시에서는 counter = counter + 1 와 같은 영역을 cirtical section, 임계 영역이라고한다.
Race condition을 해결하려면 결국 공유자원에 접근할 때 하나를 초과하는 스레드는 접근하지 못하도록 막으면 된다. 그렇게 critical section에 접근할 수 있는 스레드를 하나로 제한함을 보장하는 것을 Mutual exclusion, 상호 배제라고 한다.
어떠한 연산을 수행할 때 중간 상태가 없이 연산이 아예 수행되지 않거나, 수행이 완료되는 두 상태만 존재하는 것을 Atomic 하다고 한다. 위의 예시로 들면 중간에 다른 스레드가 침범할 수 있는 여지가 있으므로 counter = counter + 1 코드는 Atomic하지 않은 것이다.
결론
성능 향상을 위해 멀티스레드를 이용하는 것은 좋은 선택이지만, 그에 따라 각 스레드들의 synchronization(동기화)을 관리해줘야하는 의무도 생기게 된다. 다음 글에서는 스레드들간의 Mutual exclusion을 보장하는 방법인 Lock과 Semaphore, Condition variable들에 대해서 알아보겠다.
Leave a comment